Stop Treating AI Like Search
It’s Not Here to Find Answers. It’s Here to Create Them.

This essay explores how a simple design choice stops most people from getting good AI results. Whether you’re leading a team or just leveling up your own game, you’ll find some practical tips to get more from your AI tools.
🎧 Prefer to listen? I read this article on the voiceover (above), on Spotify, and on Apple.
Why This Matters
You’re wasting time and money if you treat AI1 like search. Every prompt, conversation, and half-useful output burns compute, tokens, and attention.
This is the first installment in my AI Superpowers series, and it focuses on the foundational shift you need to make today: stop treating AI like a search engine, and start treating it like a collaborator.
Except where noted, I built the included images myself using AI prompts, a little Photoshop, and lots of trial and error. Like everything else in these essays, they’re part of how I explore the intersection of technology, creativity, and culture.
The Interface Illusion
For thirty years, the web has trained us to think inside a box. A search box, that is. Type a few words, press Enter, get results. It’s clean, fast, and universal.
When generative AI arrived, designers borrowed that same search interface. ChatGPT, Gemini, Claude, Copilot—all look like upgraded search bars. The design feels familiar—and that’s the mistake. It’s one big reason so many people are disappointed with their AI results.
By giving two completely different technologies the same interface, we blurred the line between retrieval and creation. The box stayed the same. The behavior underneath changed completely, and couldn’t be more different.
We built two different kinds of tools and hid them behind the same box.
Understanding why it’s important to treat search boxes and AI input boxes differently requires a look under the hood.
Retrieval vs. Generation
Search engines, like Google or Bing, are essentially gigantic card catalogs. You ask a question, they scan a vast index of existing things they’ve seen before—websites, PDFs, images, source code, videos, etc.—and return a list of references. Essentially, the relevant things and where they can be found. Their strength is recall and ranking.
Generative AI models are different. They don’t look up answers; they compose answers. From scratch—every single time. Really. Each word in the response is a prediction. It’s the most likely continuation of the result, given everything that came before.2 That streaming text isn’t slow retrieval—it’s real-time, on-the-fly generation. I demonstrated this behavior in a previous Substack post, showing how even a simple three-word prompt leads to a unique result every time.
AI doesn’t search; it predicts.
Once the first few words are predicted3, the model loops again, and asks: what’s next most likely, given what came before? And then it loops again. And again. Each loop builds on the last until the response forms. And just like that—statistics becomes language.
To see how much that text box design choice matters, I made a cartoon (with ChatGPT and a little Photoshop) that illustrates what happens when two totally different tools hide behind the same interface. This took longer than I’d care to admit.

So if the text boxes look the same, what separates good AI use from just another Google query? Here’s the answer in one word: context.
AI Superpower #1: Think in Context, Not Questions
We open an AI chat and start typing a question. That’s what decades of search engines have taught us to do—treat the text box as a place to ask. But the AI text box isn’t for questions; it’s for adding context.
Every message you send—and every one the AI generates—shapes the model’s context. And this context shapes the overall interaction—what the model thinks about the topic you’re discussing. The context makes the model’s responses coherent and relevant. So use the AI text box as a way to share your context— your intent, your goals, your ideas, your constraints, your outcomes. The better you do this, the better your results.
Your results improve in proportion to the context you give.
The AI chat window is more than an interaction history—it’s actually the entire context for that particular thread. Unlike a search query, which forgets you instantly4, this chat window stores every message that you and the model exchange, providing source material and patterns that shape how the model behaves.
Context isn’t a prompt trick; it’s the environment that influences how the model responds. The clearer the environment, the smarter the model appears. Think of context like a notebook that fills itself as you talk—each message layers tone, ideas, and intent on top of the last.

What that “notebook” really represents is the model’s working memory—what it remembers, summarizes, and uses to predict what comes next.
How Context Actually Works
Every chat thread has its own context window—the model’s short-term working memory. It holds your messages, its replies, and the invisible logic connecting them. That history makes the conversation feel coherent, even “attentive.” But that memory isn’t infinite. Knowing how the context window fills and forgets, and being intentional about how you use it, will help you get better results.
✅ Each conversation has its own memory. Isolate tasks in separate chats. Keep related work in one thread. Start fresh for new projects.
✅ The whole conversation counts. The model rereads everything each time it replies. Long threads cost more and can drift in tone.
✅ Every turn adds weight. Be concise. Every word consumes finite context budget and compute resources. Long prompts and verbose outputs fill it faster.
✅ Memory is finite. When the window fills, older details fade, sometimes without warning. Restate key instructions in long chats.
The context window is a budget—spend it wisely.
A few years ago, context windows were tiny. Only a few pages of text. Today, they can swallow whole reports, transcripts, or codebases.
The Expanding Memory of Machines
The chart below from epoch.ai5 shows how rapidly context window capacity has expanded—a reminder that this ‘working memory’ isn’t fixed. Larger windows allow richer collaboration and longer reasoning chains—but they can also raise costs.
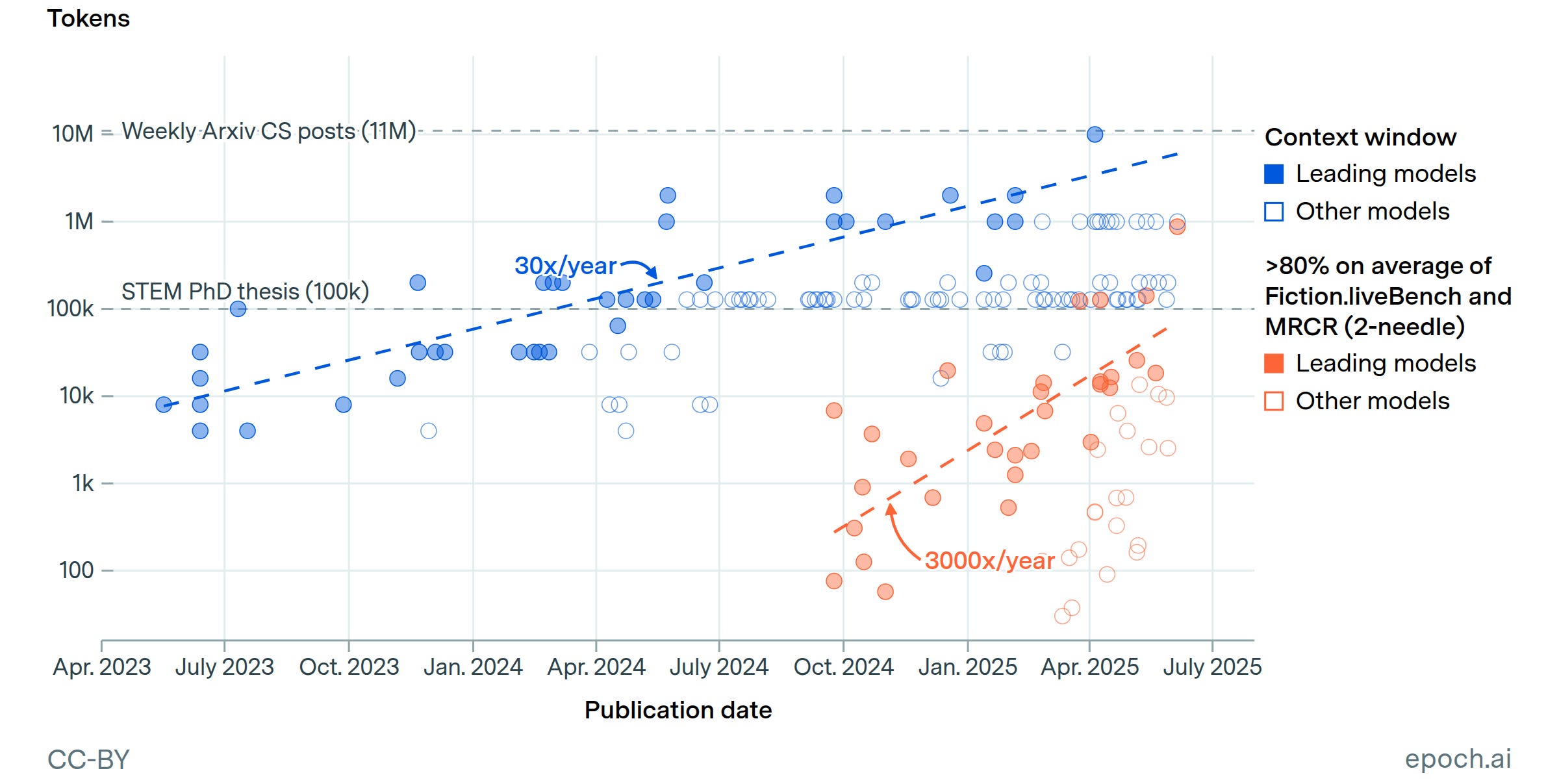
Once you understand how a model remembers, you can decide what’s worth remembering. The next step is teaching it how to think—defining roles, tone, and sequence so its reasoning matches yours. That’s where we’ll go next week in AI Superpower #2: Think in Roles, Not Rules.
🐇🕳️ Try This Next (Rabbit Hole Prompts)
Here are some fun prompts to try that will help you dive a bit deeper into this topic. You can copy and paste any of these as-is into new or existing chats. If you find anything useful or particularly interesting, let me know in the comments!
Each of these prompts explores a different dimension of the context window—what it remembers, what it drops, and how those trade-offs shape your results.
💡Prompt #1: How Big is Your Context Window?
This prompt will give you a deeper understanding of context window capacity. It’ll work on any conversation, but you’ll get more interesting results on longer threads.
Analyze this thread’s context usage. Estimate input/output tokens so far, what you think was summarized or dropped, and where additional context would most help quality.
💡Prompt #2: How Much Did it Cost?
This prompt will help you understand how costs are correlated with context window use. It works best on conversations that have had some back-and-forth, especially so where you’ve shared things like documents or long blocks of text.
Estimate total tokens and a cost range using typical API pricing for comparable models. Show assumptions.
Every interaction has a price. Long prompts, repeated uploads, and extended histories all drive up token count.
🏢 Executive Note: Poor context management quietly erodes margins. Repeated uploads of the same material, redundant chats, or overly long prompts can double or triple model usage costs without a noticeable improvement in quality.
💡Prompt #3: Who’s Really in Charge?
This prompt analyzes your conversation so far and estimates how much of the response tone and structure comes from your phrasing and guidance vs. the model’s pre-built training.
Analyze our conversation so far. How much of your generated output appears to be influenced by my specific phrasing, ideas, or tone versus your prior training? Provide your best estimate with a short rubric (tone, structure, facts, examples) and describe the results in plain language.
The better your framing and context the more the system reflects your thinking instead of its statistical defaults. Try it for yourself. Open a new chat and ask a fact-based question, like, “Why does a cat’s tail flick?” followed by this prompt. You should see that the model’s response was nearly 100% influenced by its training.
🎨 Creative note: I’ll dive in to this topic more in the coming weeks, and will be sure to share lots of tips, prompts, and other ways to get better outputs! It’s especially useful when you’re trying to use AI to invent something entirely new in the world.
💡Bonus Prompt: Context Window Meta Prompt
Ready to get meta? Try one more experiment that asks your AI to design its own context tests.
Give me 6 non-obvious, single-paste experiments to help me understand how your context window behaves. Each idea should show something new about how memory, truncation, tone, or drift work in long chats. For each, provide a short and catchy title, what I’ll see (1 line), a copy-paste prompt, and the token cost (low / medium / high). Keep it concise and practical.
This prompt will generate its own mini-lab of experiments, which should be different from model to model and tool to tool. You may learn as much from how it interprets the assignment as from the prompts it creates for you. Happy hunting!
Looking Ahead
I sometimes wonder how future generations will characterize this era, this golden age—the year 2025, when AI first became widespread. What will people think, say, 100 years from now, as they cast their learned gaze backwards through the century that is our future, towards a time which, for them, will be as archaic as 1925 is for us?
Will they regret how much we underestimated AI’s impact on the world? Or how much or how little we governed its use? Or how much energy and water and surface area of the earth we dedicated to the data centers that powered early versions?
One thing I am certain they will regret: that humans built the most transformative technology in generations—AI—and made it look like a search engine.
Putting It Into Practice and Avoiding Context Waste
This mental shift—from retrieval to prediction, from questions to context—is the first step. Applying it is where you unlock leverage.
If you’re a business leader, mismanaged context windows quietly drain productivity and budget. Every redundant upload or unfocused thread compounds costs. Teaching your team how to think about context and how to use it correctly will add value and reduce AI’s drag on your margin.
If you’re an individual, try the prompts above. Maybe provide a bit more context in an existing thread and see if the model immediately improves tone, accuracy, and relevance. You may find some threads are better restarted, if the context has drifted.
I help leadership teams audit their AI workflows—identifying where context mismanagement is leaking time and budget—and design systems that turn hidden waste into measurable advantage. If you’re ready to optimize your organization’s use of context book an introductory call ↗.
— Rob Allegar
I’m a lifelong builder and advisor exploring what happens when technology stops behaving like a tool and starts acting like a collaborator. In this newsletter, I explore the space between ideas and execution, and help people build things that matter. roballegar.com
Thanks for reading. If you enjoyed this piece, hit ♥ or share it with someone still treating AI like search.
In most public discussions, and this essay, “AI” refers to generative AI—systems that produce text, images, or code by predicting likely continuations.
Some chat platforms combine generation with retrieval or web access, but the underlying process is (usually) still token-by-token prediction.
Really it’s the first token(s), but the distinction is technical and outside the scope of this essay. If you want to dive into the rabbit hole, this is a pretty good video. [10m 58s]
Don’t worry, Simple Minds won’t forget about you like a search query. This song is one that I don’t ever seem to skip. It’ll get the full play through whenever it comes on, as long as I haven’t heard it recently. [4m 22s]
Greg Burnham and Tom Adamczewski (2025), “LLMs now accept longer inputs, and the best models can use them more effectively”. Published online at epoch.ai. Retrieved from: ‘https://epoch.ai/data-insights/context-windows’ [online resource]